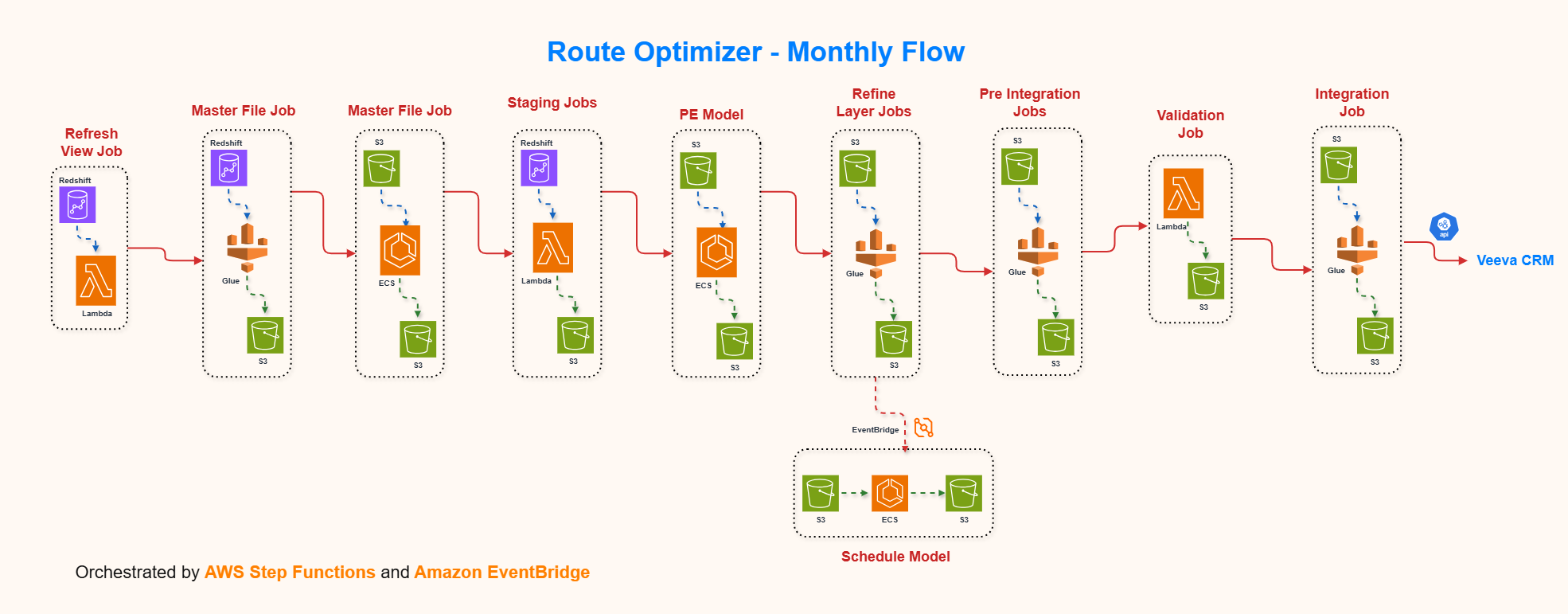
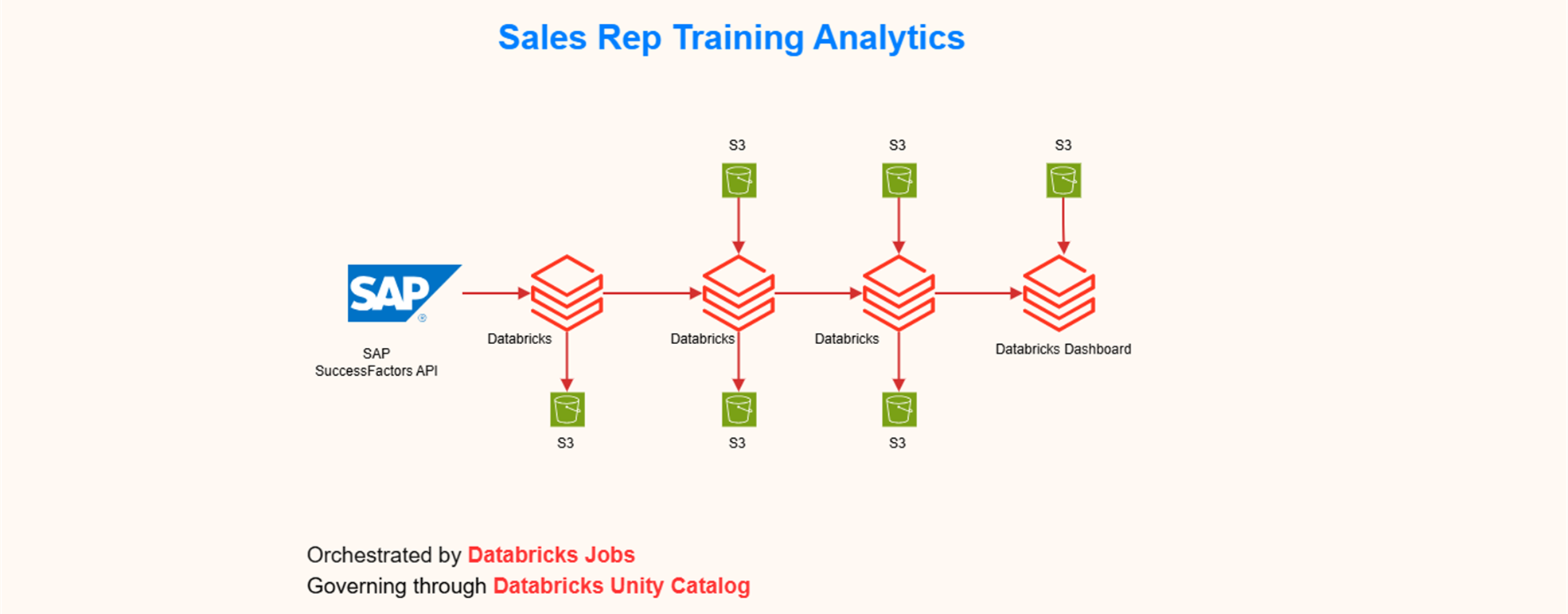
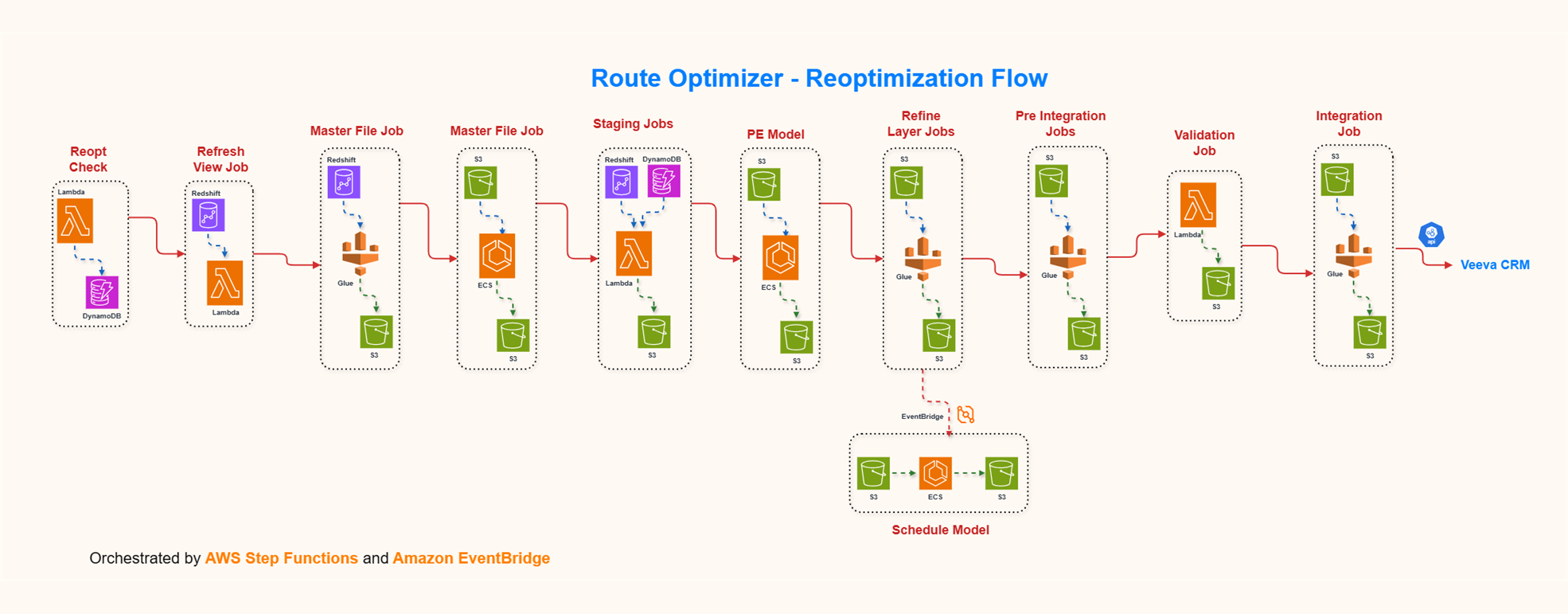
A Databricks based Sales Rep Training Analytics platform
integrating SAP SuccessFactors training data with Veeva call and
email activity to measure training coverage, completion trends,
post-training engagement, and field execution.
Technology used
- Databricks Jobs
- Databricks Unity Catalog
- Databricks Dashboard
- Python
- PySpark
- SQL
- Delta Lake
- API
- Amazon S3
- AWS Secrets Manager
Responsibilities
- Designed a Databricks-based training analytics platform integrating SuccessFactors and Veeva CRM data to evaluate sales rep training effectiveness.
- Developed scalable PySpark, SQL, and Delta Lake pipelines to process training, call, and email activity data into curated Bronze, Silver, and Gold layers.
- Built data models and reusable transformations to connect training completion with rep activity, supporting analysis of engagement, productivity, and skill gaps.
- Enhanced pipeline scalability and reliability through incremental loads, optimization, partitioning, and data quality validations.
- Collaborated with business, source system, and BI teams to deliver trusted datasets for downstream analytics and reporting.
- Supported training improvement initiatives by enabling insights into low adoption, overdue learning, and inactive rep behavior.